



I need to get all of the recordsdata for a given web site at archive.org. Causes would possibly embrace
- the unique creator didn’t archived his personal web site and it’s now offline, I need to make a public cache from it
- I’m the unique creator of some web site and misplaced some content material. I need to recuperate it
- …
How do I try this ?
Making an allowance for that the archive.org wayback machine may be very particular: webpage hyperlinks are usually not pointing to the archive itself, however to an online web page which may not be there. JavaScript is used client-side to replace the hyperlinks, however a trick like a recursive wget will not work.
ANSWER:
How one can run .sh or Shell Script file in Home windows 10
Shell Scripts or .SH recordsdata are like batch recordsdata of Home windows which might be executed in Linux or Unix. It’s attainable to run .sh or Shell Script file in Home windows 10 utilizing Home windows Subsystem for Linux. On this publish, we’ll present you the right way to run a Shell Script file in Home windows 10.
How one can run .sh or Shell Script file in Home windows 10
Bash is a Unix shell and command language which may run Shell Script recordsdata. You do not want to put in Ubuntu or every other Linux Distros until your scripts want the assist of the actual Linux kernel. We’ll share each the strategies.
- Execute Shell Script file utilizing WSL
- Execute Shell Script utilizing Ubuntu on Home windows 10
1] Execute Shell Script file utilizing WSL
Set up WSL or Home windows Subsystem for Linux
Go to Settings > Replace & Safety > For Builders. Test the Developer Mode radio button. And seek for “Home windows Options”, select “Flip Home windows options on or off”.
Scroll to seek out WSL, verify the field, and then set up it. As soon as completed, one has to reboot to complete putting in the requested adjustments. Press Restart now. BASH can be obtainable within the Command Immediate and PowerShell.
Execute Shell Script Information
- Open Command Immediate and navigate to the folder the place the script file is offered.
- Kind Bash script-filename.sh and hit the enter key.
- It can execute the script, and relying on the file, it is best to see an output.


On a Linux platform, you normally use SH, however right here it’s essential to use BASH. That mentioned, BASH in Home windows has its limitations, so if you wish to execute in a Linux atmosphere, it’s essential to set up Ubuntu or something related.
2] Execute Shell Script utilizing Ubuntu on Home windows 10
Ensure you have Ubuntu or every other Linux distros put in. Ubuntu will mount or make all of your Home windows directories obtainable beneath /mnt. So the C drive is offered at /mnt/C. So if the desktop can be obtainable at /mnt/c/customers/<username>/desktop.
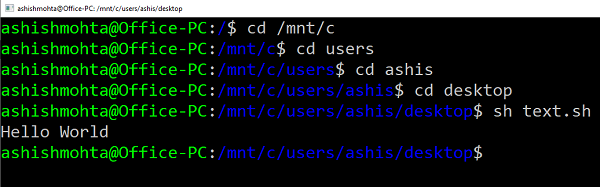

Now observe these steps
- Kind Bash in run immediate, and it’ll launch the distro immediate.
- Navigate to the folder utilizing “cd” command to the folder the place the scripts can be found.
- Kind “sh script.sh” and hit enter.
It can execute the script, and if they’ve a dependency on any of core Linux options.
I made script for downloading entire web site:
waybackmachine.sh
#!/usr/bin/env bash
# Wayback machine downloader
#TODO: Take away redundancy (obtain solely latest recordsdata in given time interval - not all of them after which write over them)
############################
clear
#Enter area with out http:// and www.
area="google.com"
#Set matchType to "prefix" if in case you have a number of subdomains, or "actual" if you'd like just one web page
matchType="area"
#Set datefilter to 1 if you wish to obtain knowledge from particular time interval
datefilter=0
from="19700101120001" #yyyyMMddhhmmss
to="20000101120001" #yyyyMMddhhmmss
#Set this to 1 in case your web page has a number of captured pages with ? in url (experimental)
swapurlarguments=0
usersign='&' #signal to interchange ? with
##############################################################
# Don't edit after this level
##############################################################
#Getting snapshot listing
full="http://net.archive.org/cdx/search/cdx?url="
full+="$area"
full+="&matchType=$matchType"
if [ $datefilter = 1 ]
then
full+="&from=$from&to=$to"
fi
full+="&output=json&fl=timestamp,authentic&fastLatest=true&filter=statuscode:200&collapse=authentic" #Type request url
wget $full -O rawlist.json #Get snapshot listing to file rawlist.json
#Do parsing and downloading stuff
sed 's/"//g' rawlist.json > listing.json #Take away " from file for simpler processing
rm rawlist.json #Take away pointless file
i=0; #Set file counter to 0
numoflines=$(cat listing.json | wc -l ) #Fill numoflines with variety of recordsdata to obtain
whereas learn line;do # For each file
rawcurrent="${line:1:${#line}-3}" #Take away brackets from JSON line
IFS=', ' learn -a present <<< "$rawcurrent" #Separate timestamp and url
timestamp="${present[0]}"
originalurl="${present[1]}"
waybackurl="http://net.archive.org/net/$timestamp"
waybackurl+="id_/$originalurl" #Type request url
file_path="$area/"
sufix="$(echo $originalurl | grep / | minimize -d/ -f2- | minimize -d/ -f3-)"
[[ $sufix = "" ]] && file_path+="index.html" || file_path+="$sufix" #Decide native filename
clear
echo " $i out of $numoflines" #Present progress
echo "$file_path"
mkdir -p -- "${file_path%/*}" && contact -- "$file_path" #Make native file for knowledge to be written
wget -N $waybackurl -O $file_path #Obtain precise file
((i++))
completed < listing.json
#If consumer selected, substitute ? with usersign
if [ $swapurlarguments = 1 ]
then
cd $area
for i in *; do mv "$i" "`echo $i | sed "s/?/$usersign/g"`"; completed #Exchange ? in filenames with usersign
discover ./ -type f -exec sed -i "s/?/$usersign/g" {} ; #Exchange ? in recordsdata with usersign
fi
gem set up wayback_machine_downloader. Run wayback_machine_downloader with the bottom url of the web site you need to retrieve as a parameter:wayback_machine_downloader http://instance.comExtra info: github.com/hartator/wayback_machine_downloader – Hartator Aug 10 ’15 at 6:32